
This article is for informational purposes only.
When people hear about artificial intelligence in medicine, they often ask a simple question: How accurate is it?
Curiously, we rarely ask the same question about human experts. Yet in respiratory auscultation, where even experienced physicians do not always agree on what they hear, accuracy is only part of the story. The more fundamental question is this: How do you teach artificial intelligence to recognize something that experts themselves sometimes disagree about?
This challenge became the starting point for one of the first large-scale efforts to build a clinically validated AI system for respiratory sound analysis. In 2019, researchers from StethoMe, Adam Mickiewicz University in Poznań, and Poznań University of Medical Sciences published a study describing not only the performance of their algorithms, but also the extraordinary scientific effort required to create a dataset that physicians could trust.
Unlike blood tests or medical imaging, lung auscultation has no objective laboratory reference standard. There is no blood marker for wheezing. No imaging test for crackles. The only available reference is the interpretation of experts - and experts do not always agree.
Previous studies have repeatedly shown substantial variability among physicians when classifying respiratory sounds. This means that before artificial intelligence can learn to recognize abnormal lung sounds, someone first has to establish what the "correct answer" actually is.
To address this challenge, researchers spent six months collecting respiratory sound recordings during routine clinical practice at the Department of Pediatric Pulmonology, Allergology and Clinical Immunology in Poznań.
What emerged was not simply another AI training dataset, but one of the most rigorously validated collections of pediatric respiratory sounds assembled at the time.
The project ultimately involved:
Importantly, these were not carefully curated laboratory recordings. They represented the reality of pediatric respiratory medicine: crying children, movement artefacts, background conversations and the many acoustic challenges physicians encounter in everyday clinical practice.
What is perhaps less obvious is the extraordinary amount of human expertise required to create such a dataset. The validation process alone required more than 2,000 independent expert assessments of respiratory recordings. When the annotation of the training database is also considered, the project likely involved tens of thousands of individual medical annotations, representing hundreds - and likely thousands - of hours of clinical and scientific expert work.
This highlights one of the most important and often overlooked facts about medical artificial intelligence:
AI systems do not become trustworthy because they use artificial intelligence. They become trustworthy because they are taught by thousands of hours of human expertise.
Perhaps the most remarkable part of the study was the creation of the reference dataset itself.
Because there is no objective test confirming the presence of wheezes, rhonchi, or crackles, the researchers designed a rigorous multi-step validation procedure involving pediatricians and acoustics experts.
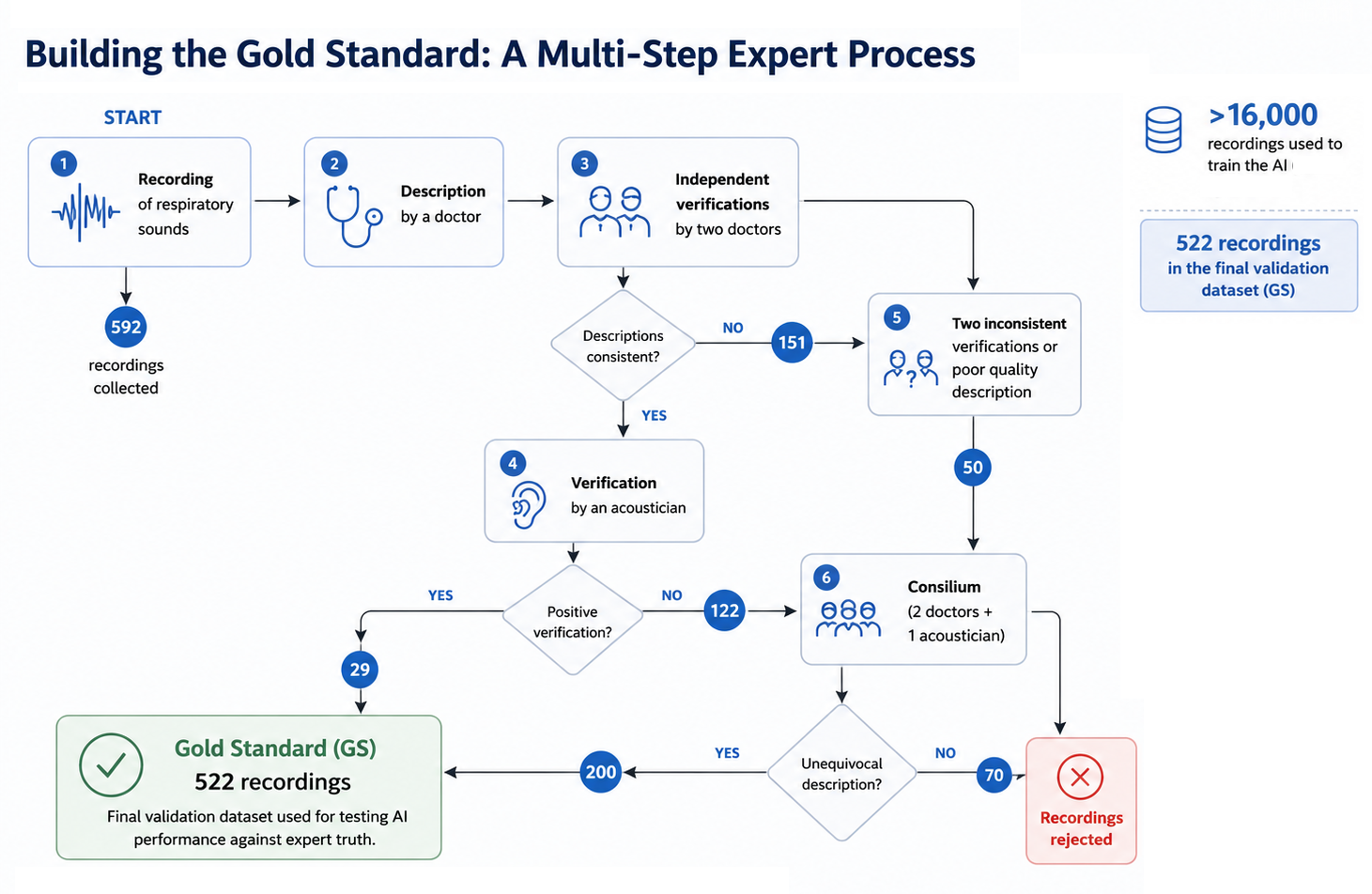
The process began with an initial physician assessment of every recording, followed by two independent medical reviews. When experts disagreed, the recordings were evaluated by an acoustician experienced in respiratory sound analysis. The most challenging cases were then discussed during face-to-face expert meetings involving two pediatricians and one acoustician. During these sessions, specialists listened to the recordings together, reviewed their visual representations, discussed possible interpretations, and decided whether the diagnosis was reliable enough for the recording to be included in the final gold-standard dataset.
The neural network was trained using more than 6000 real respiratory recordings and over 10 000 additional synthetic recordings. These synthetic recordings acted as a kind of "training simulator" for the AI, allowing it to encounter a wider range of respiratory sounds and clinical scenarios than would be possible using patient recordings alone. This helped make the algorithm more robust when confronted with the variability of real-world auscultation.
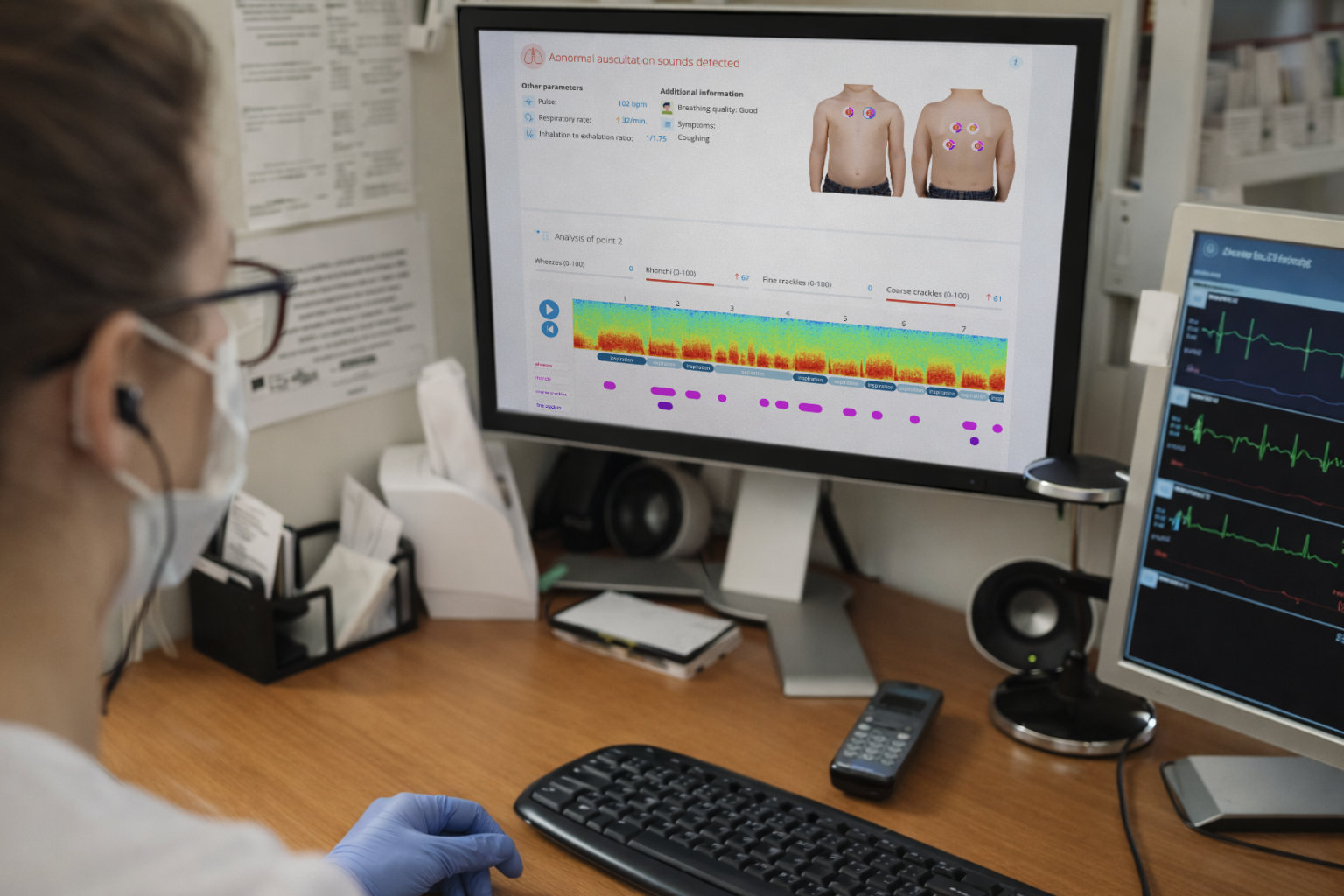
Unlike traditional algorithms that rely on manually selected acoustic features, the neural network learned directly from respiratory sound recordings and their spectrograms, allowing it to identify complex acoustic patterns associated with wheezes, rhonchi, fine crackles, and coarse crackles.
The researchers compared the performance of the StethoMe AI system with pediatricians using the independently validated gold standard dataset.
Overall, the AI system outperformed physicians across all four categories of pathological respiratory sounds. The algorithm identified approximately 13% more pathological sounds that were actually present, while its overall diagnostic performance was consistently higher than that of the physician group.
The largest advantage of artificial intelligence was observed for respiratory sounds that physicians traditionally find most difficult to classify. For example:
Interestingly, the smallest difference was observed for wheezes — one of the respiratory sounds that physicians recognize most reliably in clinical practice.
The most important finding of this work was not that artificial intelligence performed well.
The most important finding was that building trustworthy medical AI requires far more than designing a good algorithm. It requires thousands of real-world recordings, multiple layers of expert validation, interdisciplinary collaboration, and a willingness to reject uncertain data rather than force a diagnosis.
Want to monitor your child's breathing between doctor visits? StethoMe detects abnormal lung sounds at home — the same way a doctor does, but available every day.
Learn about StethoMe
